概要
LangchainのRunnableParallelを利用し、複数のモデルに同時に同じ質問をさせてみます。
使うLLMモデル
1. GPT3.5
2. Command R+
3. Groq + Llama3 70b
4. Groq + Gemma-7b
以下画像のように1つの質問に対して4つの回答が生成されます。

コード
import streamlit as st from langchain_cohere import ChatCohere from langchain.chat_models import ChatOpenAI from langchain_groq import ChatGroq from langchain_core.prompts import PromptTemplate from langchain_core.runnables import RunnableParallel from langchain_core.output_parsers import StrOutputParser from dotenv import load_dotenv load_dotenv() st.set_page_config(layout="wide") st.title("いろいろなLLMに質問する") question = st.text_area("質問", value="ネットワークの設計の効率化") template = """ あなたはプロフェッショナルなITコンサルです。 日本語で質問に対して回答してください。 回答は5つ出してください 出力は以下のようなマークダウン形式でお願いします。 1. xxxxxxxxx (50文字程度) xxxxxxxxx (内容の詳細,300文字以内) 2. xxxxxxxxx xxxxxxxxx 質問: {question} """ prompt_template = PromptTemplate( input_variables=["question"], template=template, ) output_parser = StrOutputParser() parallel_model = RunnableParallel( gpt = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0) | output_parser, command_r = ChatCohere(model="command-r", temperature=0) | output_parser, llama3 = ChatGroq(model='llama3-70b-8192', temperature=0) | output_parser, gemini = ChatGroq(model='gemma-7b-it', temperature=0) | output_parser ) result = None chain = prompt_template | parallel_model st.subheader(f"文字数: {len(question)}") if st.button("実行"): col1, col2 = st.columns(2) col3, col4 = st.columns(2) result = chain.invoke(question) with col1: st.subheader("GPT3.5") message_gpt = st.chat_message('GPT') message_gpt.write(result['gpt']) with col2: st.subheader("Command-R+") message_command_r = st.chat_message('Command-R') message_command_r.write(result['command_r']) with col3: st.subheader("Llama3-70b") message_llama3 = st.chat_message('Llama3') message_llama3.write(result['llama3']) with col4: st.subheader("Gemma-7b") message_gemini = st.chat_message('Gemini') message_gemini.write(result['gemini'])
解説
ポイントはRunnableParallelで処理をモデル並列させているところです
parallel_model = RunnableParallel(
gpt = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0) | output_parser,
command_r = ChatCohere(model="command-r", temperature=0) | output_parser,
llama3 = ChatGroq(model='llama3-70b-8192', temperature=0) | output_parser,
gemini = ChatGroq(model='gemma-7b-it', temperature=0) | output_parser
)
このモデルでchain
(output_parserをここで付けたかったんですが、うまくいかず)
chain = prompt_template | parallel_model
chainしたものをinvokeで起動することで並列で処理が動きます。
result = chain.invoke(question)
Streamlitを利用しているのでスクリプトは以下コマンドで実行します
python -m streamlit run ask_parallel.py
おまけ
LangSmithで確認できるようにしてみました(LangSmithの説明は別途気が向いたら書きます。)
LANGCHAIN_TRACING_V2=true LANGCHAIN_API_KEY="<API_KEY>" LANGCHAIN_PROJECT="usalab_llm"
先ほど書いたツールを動かすと、
LangSmithで確認をすると、4つのLLMに質問を投げて回答を受け取っていることを確認できます。
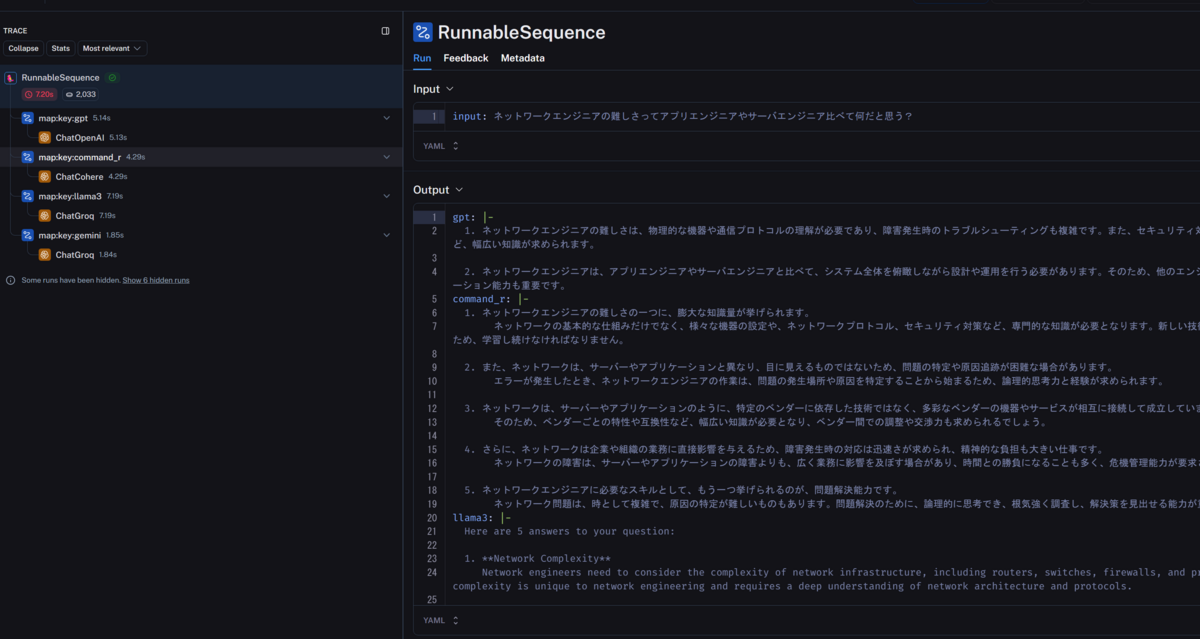
こう見ると、早いと噂のLlama3+Growが7.19sで一番時間がかかってますね~
回答の精度ですが体感としてはこの中だとCommand R+が一番よさそうです